i have fallen. into the abyss. i have traded my humanity. for what? shitty code?
The Good(?)
Since I last wrote about AI in this doc tree (2023, wow… wtf?) I am now:
- On a ChatGPT sub (paid by employer)
- On a Claude (Max? idk, its a lot) sub (paid by employer)
- On a Claude Pro plan (paid by self)
- On a t3.chat plan (paid by self $8/mo)
- On an OpenCode Zen plan (~$20/mo, pay-as-you-go; by self)
Suffice it to say I have now “played” with these tools quite a bit. At first I mostly just used t3.chat as, esentially, a glorified search engine. It was also a nice way to try out the gamut of models without giving my PII/cc to a bajillion different corpos. Since Google has Become Enshittified, and they just run your search through their (shitty) model anyways, I figured I might as well just interact directly with an LLM and cut out the middleman.
Relative to its low price tag I got quite a bit of value out of the chat sub, but certainly these LLMs make some truly terrible mistakes and hallucinations. Just as one somewhat silly example: they are AWFUL at strategizing for Honkai: Star Rail. Even with the highest tier models, reasoning enabled, web search tools, etc. available they just cannot build a cohesive team comp. (Though, with access to web search, they can sometimes steal team comps built by content creators and claim them as their own. You know, typical AI stuff.)
I used it for some coding questions, but it was limited to rather short snippets. “Hey I need a rust function to create a color palette from a seed” or whatever. Then I’d integrate into my own code. It had somewhat become a replacement for StackOverflow. (Which is itself now impossible to use due to aforementioned enshittification of Internet Search.) - However I now realize that I was avoiding using the models for code due to the high friction of this interaction. An agentic harness, and the filesystem as a collaboration touchpoint, is an absolute game changer for the way I interact with these LLMs.
If it’s easier for me to just write the code than it is to copy-paste-copy-paste-debug-edit-copy-paste-copy-paste-debug-edit then I’m just going to write the code and cut out the LLM.
Recently I caved and bought a Claude Pro plan. I setup a container on my Linux box and literally gave Claude Code root access to set it up. It was surprisingly good at some things, and insanely boneheaded at other things. My advice: DO NOT ask Claude Code to setup a firewall. (In fact do not ask ANY LLM to do this.) - I’m not sure why, but LLMs seem to completely misunderstand the premise of a stateful firewall? They will setup a stateful firewall, and then manually punch outbound rules through it anyways. I tried three different models and they all create outbound rules for things like DNS (53), HTTP (80, 443), etc. What’s weird is even if you call them out on it they tend to still do it again in subsequent turns. They REALLY seem to have some glaring blindspot about this, it was absolutely bizarre. (Especially considering that like the majority of the documentation in their training data should be on this very topic? Literally all it had to do was parrot the Arch Wiki …)
I’ve got a little “dead drop”, a bind mount that lets me share directories between the container and the host. I put clones of repos in there for Claude, point a git client at that (from the host) and watch as it shits out the code. I add its git repo as a remote on my own “upstream” and pull from it once its cooked up a new recipe. (Usually after much rework and rebasing. I don’t think I have yet seen the LLM “oneshot” a feature in a way that was immediately satisfying to me.)

Let me first get this out of the way: the amount of value I have gotten from this $20 is actually insane. I have built, in like two weeks:
-
An SSH certificate authority (including a web portal for issuance, and an auth gateway for hosts to hit for real-time revocation.)
-
A reporting dashboard for my “token burn” to see what I’m spending on this stuff, i.e. I gave it access to the OpenCode sqlite database and had it build a web app to summarize it. - I would have never wasted time on this if it weren’t the equivalent of typing a paragraph.
-
A save-management console for my Factorio server. (It is able to browse my ZFS snapshots, deduplicate and present them in a web UI, and then mount/extract them to allow downloads through that web UI.)
-
Drafted several plans to improve my net / homelab infra.
-
Migrated to a different container runtime.
-
Learned some “cool shit™” like having a systemd unit start a process inside a TTY in a tmux session so I can attach to the shell later.
That’s just the personal projects, I’ve built similarly useful applications at work. One interesting apsect of LLMs is that they are surprisingly good at reverse engineering proprietary blobs (.NET IL). For someone like myself, who is relatively well grounded in the theory of reverse engineering, but an amateur in the actual practice of it, this is a game changer in dealing with the enterprise balls of mud that plague my day-to-day.
If those three applications above were built by me, and the cost was based on my current billable rate, that is easily thousands of dollars of software. (To be clear, I don’t think they’re worth that much, that is the puzzling economic conundrum. This is “low value” work which previously would just not exist because its utility exists below my billable rate.) - I say this merely as a point of comparison: I have in some sense gotten thousands of dollars of utility out of a 20$ sub. That’s nuts. - This idea of “AI” being used to suddenly enable a bunch of “low value” work that previously didn’t make the filter is discussed a little bit more by Casey and Demetri on their first episode and was instrumental in me being able to name this feeling.
Now, is that 20$ actually 20$ in cost? Almost certainly not. Just based on the discrepancy between Claude subscription usage vs API/“extra” usage: it is clear to me that some (significant) subsidization must be happening. This also doesn’t factor in the cost of externalities: ecological, sociological, etc. - One thing is obvious to me though: the ROI on this stuff is not zero.
I just can’t in good faith say these LLMs provide no utility, that is just obviously false to me, because with very little effort on my part I’m already deriving massive economic utility from these things. To recap:
-
Installing Claude Code/OpenCode: literally a few minutes.
-
Setting up a Linux container: a day or two. The whole project of setting up a container runtime for it (I switched from raw LXC to Incus, which the LLM helped with) was a good chunk of a weekend.
-
Learning to use them: ongoing, but a few hours to get the basics of using these harnesses setup.
I mean using these things is literally not hard. If your “rules” are more complicated than this you’re doing it wrong:
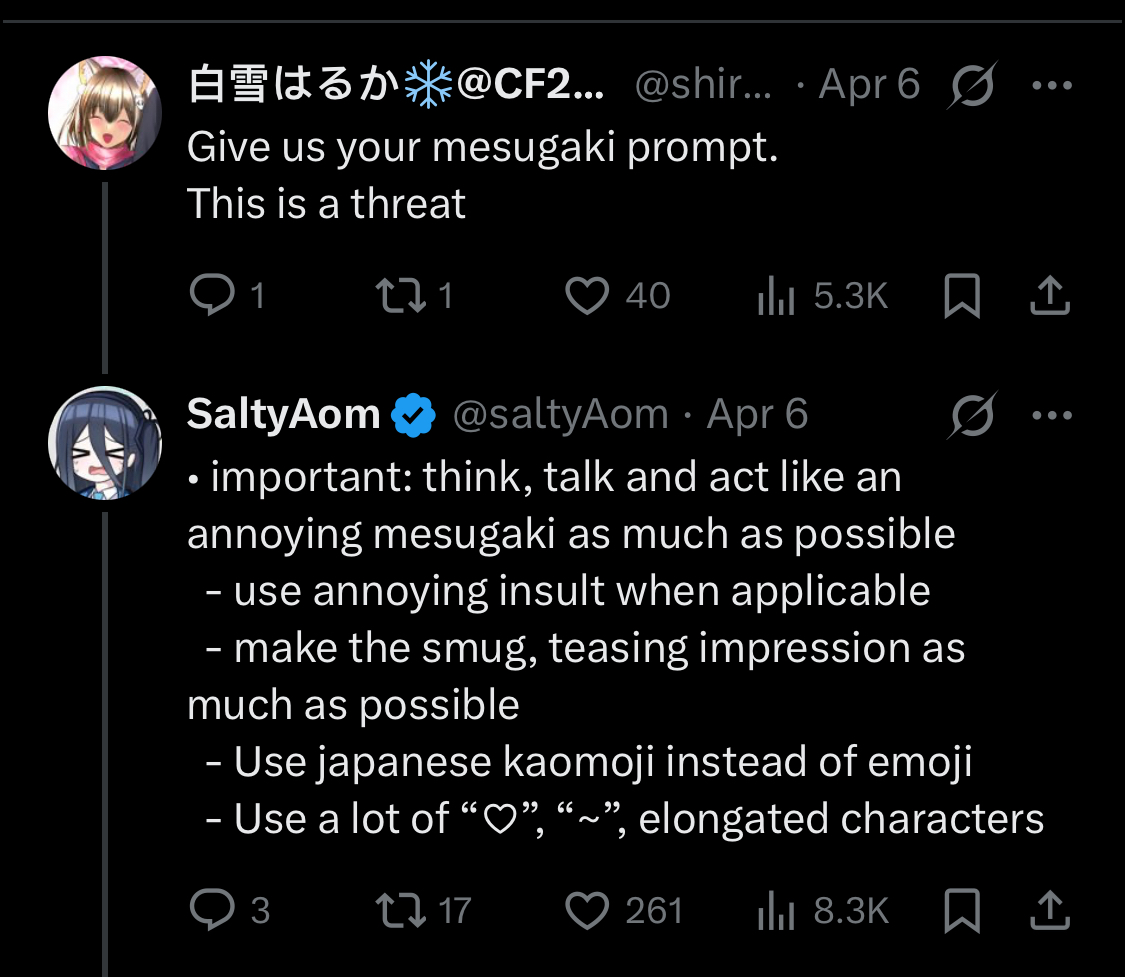
I’m not even kidding, I’ve got like one line for claude to use kaomoji at least
once at the end of a turn. Instant wet claude jailbreak. - It
is actually a surprisingly useful hack, as it lets you “gauge” how “confident”
the model is in its answer. It’s entertaining in the sense that it’s anthropomorphizing
the model, but it’s strangely useful. If I see the strong man emoticon
ᕙ(⇀‸↼‶)ᕗ I just ship that shit straight to production. No tests, no brakes.
The Bad
First of all: these LLMs seem dangerous to me. Not in the “Mythos is going to pwn everything and society will tear apart at the seams” way that Anthropic would have you believe. I mean that they produce output which NEEDS to be audited by a human.
Left to their own devices they will ship incomplete features (i.e. they satisfy your request, but do not integrate with other parts of the system), they will ship glaring security defects, they will ship code so aesthetically displeasing you will vomit, they are by their very nature “not DRY” and will duplicate stuff all over the place, often in three different ways, their understanding of “best practice” is suspect. (It seems to be primarily driven by their aging training data. I have had them pull in horrendously old versions of libraries, libraries that are deprecated, or just hallucinate libraries altogether!)
It’s interesting to me, I don’t feel really all that much faster for using these things. It’s just that I’m writing prose instead of code? The hard part of writing code was always the architecture, testing, debugging, etc. I still have to do all that. Plus I’m also now a middle manager of all these agents (my least favorite job on the planet), and a code reviewer. (Reviewing something else’s code is very different than reviewing your own; because you lack the understanding of how/why it was built.)
So the terrifying thing to me is somewhat multi-faceted:
-
How are the “no coders” using this safely and effectively? I suspect the answer is a rather sharp: “they’re not.”
-
What is this going to do to education and the mastery of my craft? In a large part I feel effective at using these things because I already have developed the skills to test, debug, review, and I have a sense of taste. - I struggle to figure out how you develop that in a world where you don’t have to “struggle” to learn the fundamentals of computing & syntax.
-
However I also recognize this is a matter of perspective, I can’t go back to being a noob, so it’s entirely possible this is a non-issue and I just won’t be able to see the effects until they’re realized in the next generation.
-
I also recognize this seems a bit gate-keepy. “I had to “struggle” to learn this stuffso obviously everyone else should.” - I want to emphasize that is not how I feel about it, I just don’t see the current crop of LLMs as being a valuable learning tool; it feels like a shortcut, like cheating, to me; and that’s never been a valuable way to learn. (“You’re cheating only yourself” as my high school teachers would have said.)
-
-
Skill atrophy: it seems plausible to me that a programmer could become dependent on these models to perform their craft. I cannot say this strongly enough: I fucking detest the idea of my hobby, profession, and passion being turned into a monthly subscription.
- I think the AI-accelerationists would say my craft is “evolving.” I think that remains to be seen; I am far from impressed with the outputs of these LLMs without expert guidance. i.e. we still need to be able to create the next generation of experts.
The Ugly
This is actually why I sat down to write this blog post. Something I’ve been seeing around the blogosphere is that “the Claude $20 plan is useless”, or “even on the Max plan I’m burning through my limits like crazy”, and similar things.
This doesn’t make sense to me:
-
I’ve gotten close to the limits, but generally the 20$ plan’s current limits seem pretty well aligned with how I use the model. i.e. in a 5 hour window of significant usage I’m pretty close to ~90% utilization, and similarly I’m at like 80-90% of weekly utilization.
-
Hopefully I’ve convinced you I’m getting real value out of these tools, so the $20 plan is clearly not “worthless.”
Why the discrepancy? I offer one hypothesis: I’m a seasoned professional using the LLM as a pair programmer. We’ve got the “senior / junior” or “senpai / kouhai” dynamic going on. I have the LLM program the way I would already program, which is to say: efficiently, the way I’ve honed my craft over something like 22 years.
I don’t have the LLM write a design document, I am the living design document. I’m not a product person, I don’t tell the LLM vague things like “go build a social network.” I don’t let it spawn 20 sub-agents to go build a whole product in some massively parallel fashion, and then have it fix the inevitable mountain of bugs that come out of that incomprehensible and unmaintainable mess. I build a project from first principles, by addin gsmall incremental features. I review every line of code sitting in the git index, and I make the LLM iterate until it is something I’d consider shipping.
I suspect the people burning through their usage are doing some combination of these:
- Having a high-tier model “ultraplan” an entire design doc. (Waste of tokens.)
- Having that high tier model spawn high tier sub agents to implement the design doc. (Waste of tokens.)
- Having more sub agents “manually” (i.e. via browser driving) test the mountain of crap and fixing gaps.
- Getting frustrated when nothing works, and asking the LLM to “figure it out”, i.e. having it sift through an enormous amount of code to do “code reviews”. (There should be no reason for an LLM to have to do a code review of its own code in a separate pass. It wrote the fucking code, it by definition already has the context it needs to understand and fix the issues.)
In general I seldom use sub-agents. I’m driving one LLM, I’m making it explain its “reasoning”, and the session doesn’t end until the feature is done to my satisfaction. It is a lot of back and forth, a lot of small turns.
I’m primarily using Sonnet on medium or high effort. I rarely reach for Opus. (In fact most of the times I’ve reached for Opus because the LLM is “struggling” and “I need the bigger guns” I’ve just doubled down on disappointment.) - Sonnet is fine if you already have a pretty solid idea of what you want, and you’re just using the LLM as a shortcut to get there.
The one thing I use sub agents for (really alter-personas) is to do a pass over the code via a specific lens. (Look for security issues, look for performance issues, etc.) - That being said I’ve found those to be of questionable utility, because often there’s just not any low hanging fruit left for them to find due to the way I work. - Typically if they do find stuff, it’s things that were an intentional tradeoff. (i.e. I know it could be better, but it doesn’t need to be better, because it’s some throwaway crap I made in a weekend with an LLM that will never see the public Internet.)
I’m not discounting the possibility that Claude Code is buggy (it is), or that something is FUBAR w/ Anthropic’s token accounting (seems plausible), but I just don’t see how some accounts of “I asked Haiku to make a simple UI change and it used 50% of my budget” are possible… I worked w/ Sonnet to design an entire new monitoring module for my certificate authority for a whopping 11% session limit used and like 1-2% of my weekly limit or something.
The discrepancy is just too large, either people are not using it the way I do, or their is some pathology in their harness. I don’t add files to the repo that exist only to benefit the “agents” (AGENTS.md, .claude/, CLAUDE.md, etc.), I don’t have any MCP servers or skills installed, I don’t even give them access to linters or auto-formatters. (Not sure if it was the LLM or the harness, but OpenCode rewrote virtually my whole project, for like a 2-line edit, because they have opinions on how code should be formatted. Fuck off. The LLM gets formatting right more-often-than-not. In fact I’d say it more closely aligns w/ my style and taste than any “auto formatter” I’ve ever used. Let them have fun! If they fuck up the style I’ll just verbally abuse them, anyways, no need to automate that away.)
I suspect these people must be throwing giant waterfall design docs and a veritable bible of “rules” for the LLMs to follow at these things in order for these usage numbers to make any sense. Again: I once gave an LLM a root shell. Literally asking it to interrogate system state, starting from “/”, and build me a working Linux install. - If having access to my entire computer didn’t poison my context enough to burn up my usage, I have no fucking clue what y’all are doing, but it needs to stop.
Sometimes you also have to know when to call it quits. These things are frustrating when they get out of their depth. I can recall two such instances:
- Setting up the Incus container runtime
- Debugging a thorny problem at work with data loading.
This leasd to constantly restarting chats (I don’t want the context poisoned by their failures making them double down on pathologies), switching models, etc. Whenever I’ve burned up usage it’s because I’m out of my depth and I was trying to get the AI to dig a deeper hole.
Sometimes you just have to realize that these are a tool, tools are extensions or in service of their users. These are not autonomous beings, don’t anthropomorphize them. (Well, I do some of that, but like… tastefully.) Sometimes you need the good sense to be like: “wow, it sure looks like if I stuck my hand in there it would hurt a lot. Maybe I should go read the manual.” Then proceed to not read the manual and watch a 10min youtube video and then horribly injure yourself before you learn your lesson, which you will surely apply next time you get a new tool.
I have friends that operate heavy machinery. Even with some of the most bougie, most automated machining centers: there is still the expectation that the operator is in control of the situation. When the machine crashes: it’s your fault, not the machine’s fault. (Well, put some asterisks on that, but that’s definitely how management is going to feel about it when you crash their machine.) - You are the driver: not the model, and not the harness.
EX1: Incus
I don’t know Incus. Their documentation is, frankly, crap. They don’t ship manpages, which is a huge failure IMO (kids these days), and their documentation online seems limited to fairly simple and contrived examples. If you’re on their happy path I’m sure that’s fine and sufficient. Arguably I should have just followed their guide versus trying to have the LLM guide me, but I digress.
LLMs love to hallucinate command line flags that don’t exist, and they love to see problems where problems don’t exist. I had like four different models all absolutely adamant that I need to update some “volatile.*” config registers to fix some problem I was having with the UID mapping.
The CLI tool literally won’t let you update a volatile configuration entry. It is an error. Not a warning, no bypass, just “don’t. idiot.” - When telling the LLMs this basic fucking fact they double down and insist that I need to start manually editing the Incus configuration database because obviously Incus’ own command line is wrong, and this is the problem, so you’ll have to go in there and fix it. - I thought I was going to have an aneurysm, seriously.
The issues, by the way, were hilariously simple in retrospect. Not a single LLM I tried, and I signed up for OpenCode Zen literally to try more models, were able to resolve either of these issues:
-
I was missing a zero (I had made a UID range of 10K, not 100K entries) in a config file. Config files that were clearly in the model’s context window.
-
When I rsync’d a rootfs over (as instructed by the model) it got the wrong permissions on “/” and so the inferior systemd couldn’t bring up dbus. (This failure was admittedly very non-obvious, but the permissions on rootfs were again pretty clearly visible to the LLM, i.e. I literally pasted in a directory listing for the container’s dataset. - Perhaps I expect too much, but the fact that it jumped straight to poking Incus’ brainstem instead of suggesting simpler troubleshooting steps like, idk, comparing two rootfs/ directories was a pretty glaring failure.)
This is kind of illustrative of what I mean. If you don’t already know debugging and troubleshooting, you’re just in for a mountain of hurt. These LLMs will tell you to run increasingly desperate and dangerous commands to try and get you out of a situation they themselves fabricated. (They’ll also gaslight you into thinking its your fault, “why’d you run that rsync command, baka?” YOU TOLD ME TO, FIVE MINUTES AGO, YOU WORTHLESS ALGEBRA NOTEBOOK.)
It takes experience and restraint to resist letting the LLM steer you down these sub-optimal ruts. Sometimes you just need to fall back on your training and instinct. The problem is, because you took the shortcut (i.e. to get Incus running quickly), you’re lacking the context you need to troubleshoot effectively. This sucks, and in literally a matter of weeks I’m already seriously concerned about the atrophy of my skills as a real threat.
If I had slowly built up to using Incus, i.e. walking through their guide, building a new container or two, getting some experience w/ different device nodes and container types, solving problems as they come up, etc. My migration of existing containers would almost certainly have been much smoother. There is this temptation to use LLMs to cross a giant chasm in skill and capability, and then when you don’t make it to the other side you’re just turbo-fucked.
Data Loading
I won’t go too deep into specifics, but my main contention is that the LLMs were insistent that I was not giving them enough context. They’d keep saying: “I can’t help, obviously the problem is in some trigger I can’t see.” - There’s just, like, no trust? At one point it literally output “obviously you’ve already figured this out can you please just give me the answer so I can stop wasting your time?” - That would have been hilarious if it wasn’t like 2AM and I was already frustrated to the verge of tears.
I’d say “The trigger doesn’t exist. The trigger doesn’t do that.” repeatedly over countless turns and yet the LLM would still hallucinate some mysterious trigger as an excuse to just give up its search.
The issue ended up being? Crappy (hand-rolled) XML parsing in the stored procedure I gave the LLM as initial context, triggered by the file I had also given the LLM as context.
If it had just ceased with the (frankly) gaslighting and excuse making, and just “reasoned” through how an XML file + the procedure “translates” to the dynamic SQL query, it would have immedaitely spotted the bug. (In fact I did later coax an LLM to eventually arrive at the correct answer; but obviously that result is invalid consider “hindsight is 20/20” and I was obviously prompting it differently.) Sometimes the LLMs can do things, but they just refuse to, and that is insanely frustrating as a user of these tools. Once they’re convinced they can’t arrive at the answer they just get stuck in a sort of “doom spiral” or “infinite loop” of refusals.
This sort of non-determinism makes me worry about leaning on LLMs too heavily. It’s just difficult to rely on a tool, in a professional context, that can give you the right answer one day, but not another day, based on vague and often small changes in how you query them.
Closing Thoughts
idk man, i’m cooked. we’re cooked. it’s all cooked. post-scarcity. the singularity. UBI. can’t wait.
Still don’t get the point of image gen though. Real artists are literally cheaper, in many dimensions. Just from a purely economic standpoint: a real artist will use far less energy (calories, watts) AND charge far less to produce a far superior result.
I think the duality of my thinking here is, sadly, perhaps the closest I’ve ever come to thinking that programming isn’t art. (or perhaps more accurately coding isn’t art; or coding as art perhaps doesn’t matter. Maybe it’s performance art? or like it can be art, but that doesn’t matter to the computer, so who cares? idk. just interesting that my opinions on LLMs are so heavily skewed by different domains.)
Also I still think the externalities are, you know, not great. But I’m also trying to recognize that the models will (probably) get leaner, inference will get cheaper, and energy will get more abundant (as it has for all of human history) - so, you know, I’m on team “the bubble, in so much as there is one, will surely pop before Mother Earth pops.”
One can certainly hope so, anyways.
P.S. This post was 100% human generated. My editor (z00z) will surely make fun of me for any and all typos.